.webp&w=3840&q=75)
How ClickUp Enables Outcome-Based Project Management (Not Just Task Tracking)
🕓 February 15, 2026

You rely on security and speed every day when you interact with digital systems, from logging into your email to using a mobile payment app. But have you ever wondered how these systems protect your sensitive data, like your hash function password, while ensuring quick access? The secret weapon is often the hash function algorithm.
A hash function is nothing but a mathematical algorithm that acts as a digital fingerprint generator. It takes any input data—which we call a "message" or "key"—and transforms it into a fixed-size string of characters, known as a hash value or message digest. This process, called hashing, is one of the most fundamental concepts in computer science and network security.
Why should you care about this technical process? Because the integrity and security of your data depend on it. This content will walk you through the core concepts, show how hash function works, and help you understand why certain hash function types are essential for modern digital life.
A hash function definition is simple: it is a deterministic function that maps input data of arbitrary size to an output of a fixed size. The input can be a single number, a long text file, or even an entire database. No matter the size of the input, the resulting hash, or digest, always maintains the exact same length.
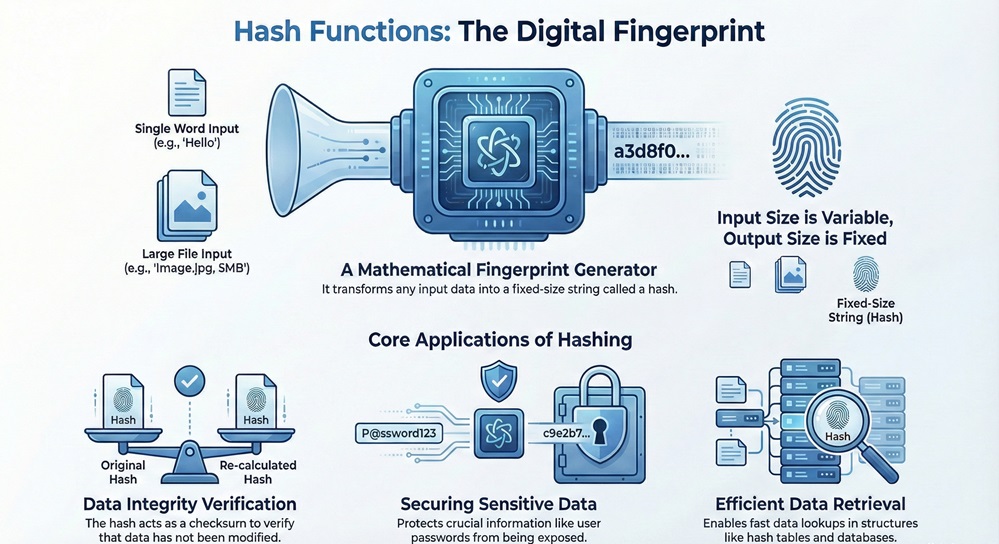
This process serves as a highly efficient tool for several key purposes:
The resulting hash value for a specific input is always the same. If you run the word "Orange" through a hash function algorithm like SHA-256 today, you will get the identical output a year from now.
However, if you change even a single comma or a single letter in the input—for example, changing "Orange" to "orange"—the resulting hash value will change completely. This critical feature is called the Avalanche Effect. This effect ensures that a tiny modification in a large document immediately results in a drastically different digital fingerprint, making any tampering immediately obvious.
Understanding how hash function works requires focusing on its one-way nature. It is easy to compute a hash from an input, but it is computationally infeasible to reverse the process and get the original input from the hash value. This makes the hash function algorithm a one-way function.
The general process of calculating a hash value involves these steps:
This sequential, block-by-block mixing of data is what creates the strong interdependency where a single change affects the entire final hash.
Also Read: Quantum Cryptography - QKD, Security & Future Guide
A good hash function needs specific qualities to be reliable, especially for applications like hash function security. These hash function properties ensure the hash value is useful and the process is trustworthy.
Deterministic
A hash function is deterministic, meaning the exact same input always generates the exact same output. This is a primary feature, as consistent output allows systems to verify data integrity and compare passwords effectively.
Fixed-Size Output
No matter the input's size, the resulting hash always has a predetermined, fixed length. For example, a 1-character text, a 100-page document, or a 2 GB video file, when run through SHA-256, will all produce a hash that is exactly 256 bits long (or 64 hexadecimal characters). This ensures consistency and makes data management more efficient.
Pre-Image Resistance (One-Way)
This property means that given the output (hash value), it is computationally infeasible to figure out the original input (pre-image). This is crucial for securing a hash function password. If an attacker steals the stored hash, they cannot easily reverse it to get your original password.
Collision Resistance
Collision resistance implies it is computationally very difficult to find two different inputs that produce the same hash value. This is called a hash collision. While mathematically possible, strong algorithms are designed to make finding a collision take an impossible amount of time and computing power. This property is paramount for ensuring hash function security and data authenticity.
Speed of Computation
The algorithm must generate the hash quickly, especially for non-cryptographic purposes like in a hash function in dbms or for file indexing. Fast computation ensures that data retrieval remains efficient, which is the whole point of using a hash table in the first place.
Hash function types fall into two main categories: non-cryptographic and cryptographic. Both types use the basic principles of hashing but prioritize different properties.
1. Non-Cryptographic Hash Functions
These functions prioritize speed and good distribution over absolute collision resistance. They are commonly used for data indexing and error checking.
2. Cryptographic Hash Functions
Cryptographic functions meet a stricter set of security requirements, including strong collision and pre-image resistance. They are vital for hash function in network security.
Also Read: What is Sandboxing in CyberSecurity? How It Works?
The Secure Hash Algorithm (SHA) family represents the modern standard for hash function security.
The use of a hash function is much more widespread than you may realize.
Hash Function Password Storage
The system never stores your actual password in its database. Instead, it stores the hash of your password. When you log in, the system runs your entered password through the same hash function algorithm and compares the resulting hash to the one stored in the database.
This method ensures that even if an attacker hacks the system and steals the database of hashes, they cannot use the hashes to log in or easily reverse them to get your original hash function password. This is a core component of hash function security.
Data Integrity and Verification
When you download a file, the source website often publishes a hash value alongside it. After the download is complete, you can run the file on your local machine through the same hash function algorithm to generate a local hash.
Hash Function in DBMS and Hash Tables
In database management systems (hash function in dbms), hash functions create hash tables for incredibly fast data lookup. The hash function takes a data key (like a customer ID or a product name) and converts it into a small integer, which is used as an index to a specific location (or "bucket") in the database.
This method allows the system to directly access the data's location without searching through every entry, significantly improving speed and efficiency. The goal here is uniform distribution of keys to minimize collisions and ensure quick access.
Also Read: What is Edge Computing? How it Differs from Cloud Computing?
While both hashing and encryption deal with data security, they serve fundamentally different purposes. It is important to know the distinctions.
| Basis for Comparison | Hash Function (Hashing) | Encryption |
|---|---|---|
| Primary Goal | Data integrity and verification (One-Way) | Data confidentiality and secrecy (Two-Way) |
| Output Size | Always a fixed length (e.g., 256 bits) | Output size is often the same or larger than the input |
| Reversibility | Irreversible (one-way function) | Reversible (two-way function) using a secret key |
| Key Requirement | Does not require a key | Requires an encryption key and a decryption key |
| Best Used For | Hash function password storage, data integrity, indexing | Securing data transmission (e.g., HTTPS, VPNs) |
The humble hash function is one of the most critical, yet often unseen, components of modern computing. Whether speeding up data retrieval in a hash function in dbms, ensuring the integrity of a file, or protecting your hash function password with unbreakable digital fingerprints, the hash function algorithm plays a vital role. You gain efficiency, reliability, and hash function security by mastering the core properties like determinism, fixed output, and collision resistance.
As a client, you need partners who understand the technical depth required to safeguard your digital assets. We focus on implementing and maintaining the most secure standards, such as SHA-256, across all systems.
Contact us today to learn how our expertise in robust network security architecture can ensure the complete integrity and safety of your most critical data.

A hash collision occurs when two completely different inputs produce the exact same hash value output. While mathematically inevitable in any fixed-size output system, a good hash function algorithm, like SHA-256, makes finding a collision extremely difficult to the point of being practically impossible.
In hash function in network security, the hash function creates a Message Authentication Code (MAC) or is used for digital signatures. The sender hashes the message and includes the hash. The receiver calculates a new hash upon receiving the message. If the two hashes match, it verifies both the sender's authenticity and that the message has not been altered during transmission.
SHA-256 is currently the industry-recommended hash function for most security applications. It is part of the SHA-2 family. While newer algorithms like SHA-3 and BLAKE2/BLAKE3 offer different structures and performance advantages, SHA-256 remains an extremely robust and widely accepted standard for hash function security.

Surbhi Suhane is an experienced digital marketing and content specialist with deep expertise in Getting Things Done (GTD) methodology and process automation. Adept at optimizing workflows and leveraging automation tools to enhance productivity and deliver impactful results in content creation and SEO optimization.
Share it with friends!


.webp&w=3840&q=75)



share your thoughts